반응형
MS에서 발표했다는 내용입니다.
VALL-E 데모 github
아래 깃헙에 있는 내용을 참고했습니다.

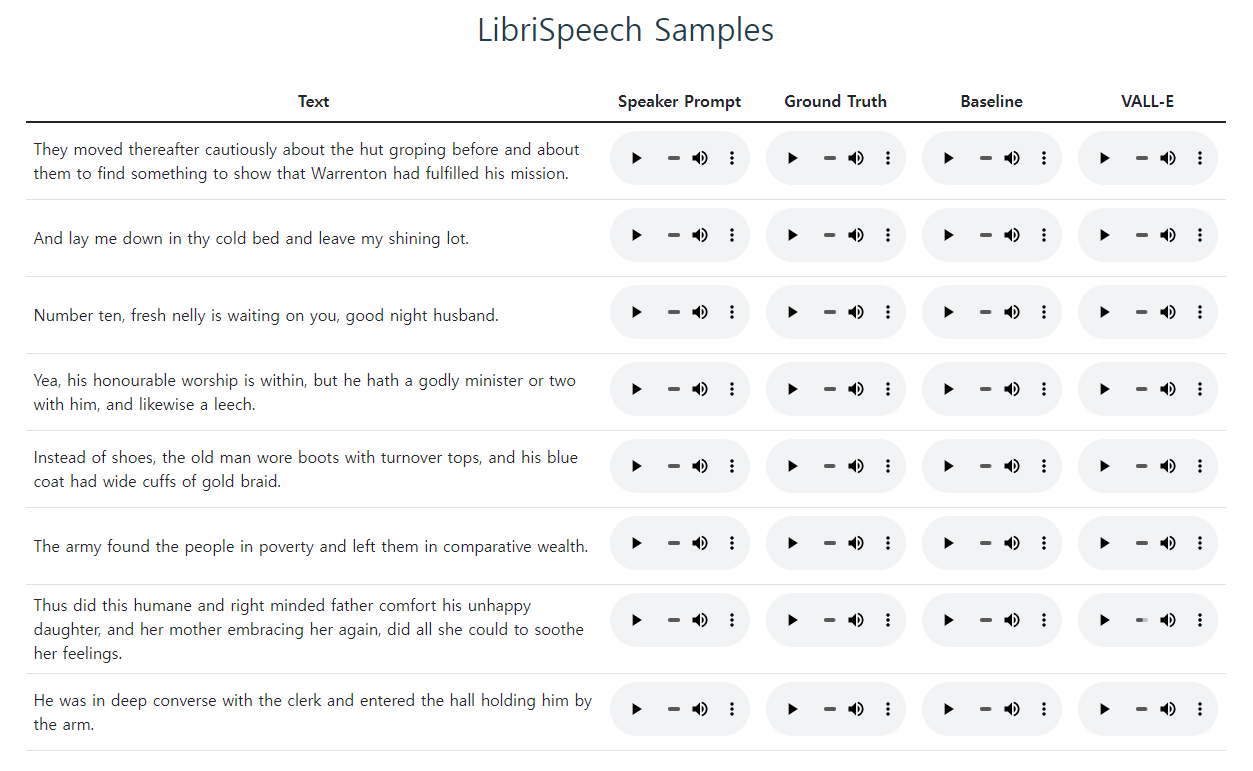
3초 음성 샘플로 만들 수 있다는 기술입니다.
텍스트를 입력해놓고, 3초 샘플 음성을 추가하면 이에 맞게 새로운 AI가 생성한 오디오가 출력되는 구조입니다.

그 이후에는 여러가지 샘플들이 있습니다. 다양한 소리를 들어볼 수 있으니 한번 들어보시면 좋을 듯 합니다.




마지막에 써있는 윤리성명입니다. 잠재적 위험이 있기 때문에 음성 합성에서 동의를 받아 실험을 수행했다고 합니다. 일반화될 경우 합성 음성 감지 모델을 포함해야한다고 나와있습니다.
위에 윤리성명에 나와있듯이 아직 범죄악용 위험성을 고려해서 대중 공개는 안했는데, 보이스피싱 같은 범죄에 쓰인다면 당할 사람들이 더 많아질 것으로 생각됩니다. 합성 음성 감지 모델 포함해야한다고 되어 있듯이, 역으로 AI인지 여부를 알려주는 프로그램까지 같이 개발되었으면 좋겠습니다.
반응형
'정보' 카테고리의 다른 글
| 2023년 서울 택시요금 인상, 2월 1일부터 (기본요금, 구간요금, 시간요금) (0) | 2023.02.01 |
|---|---|
| 한눈에 보는 연말정산 (0) | 2023.01.04 |
| 2023년 서울시 교통비 인상, 언제? 얼마나? 할인방법은? (0) | 2023.01.02 |



댓글